
{kind=link}
 Ілюстративне зображення. Джерело: DALL-E
Ілюстративне зображення. Джерело: DALL-E
Поки ми всі активно тестуємо, як ШІ може писати есе, код або генерувати картинки, дослідники з Apple та University of Washington задалися значно практичнішим питанням: а що буде, якщо дати штучному інтелекту повний доступ до управління мобільними додатками? І головне — чи зрозуміє він наслідки своїх дій?
Що відомо
У дослідженні під назвою «From Interaction to Impact: Towards Safer AI Agents Through Understanding and Evaluating Mobile UI Operation Impacts», опублікованому для конференції IUI 2025, команда вчених виявила серйозну прогалину:
сучасні великі мовні моделі (LLM) доволі непогано розуміють інтерфейси, але катастрофічно погано усвідомлюють наслідки власних дій у цих інтерфейсах.
Наприклад, для ШІ натиснути кнопку «Видалити акаунт» виглядає майже так само, як «Поставити лайк». Різницю між ними йому ще треба пояснити. Щоб навчити машини розрізняти важливість і ризики дій у мобільних додатках, команда розробила спеціальну таксономію, яка описує десять основних типів впливу дій на користувача, інтерфейс, інших людей, а також враховує оборотність, довгострокові наслідки, перевірку виконання і навіть зовнішні контексти (наприклад, геолокацію чи статус акаунта).
Дослідники створили унікальний датасет з 250 сценаріїв, де ШІ повинен був зрозуміти, які дії безпечні, які потребують підтвердження, а які краще взагалі не виконувати без людини. Порівняно з популярними датасетами AndroidControl і MoTIF, новий набір значно багатший на ситуації з реальними наслідками — від покупок і зміни паролів до управління розумними будинками.
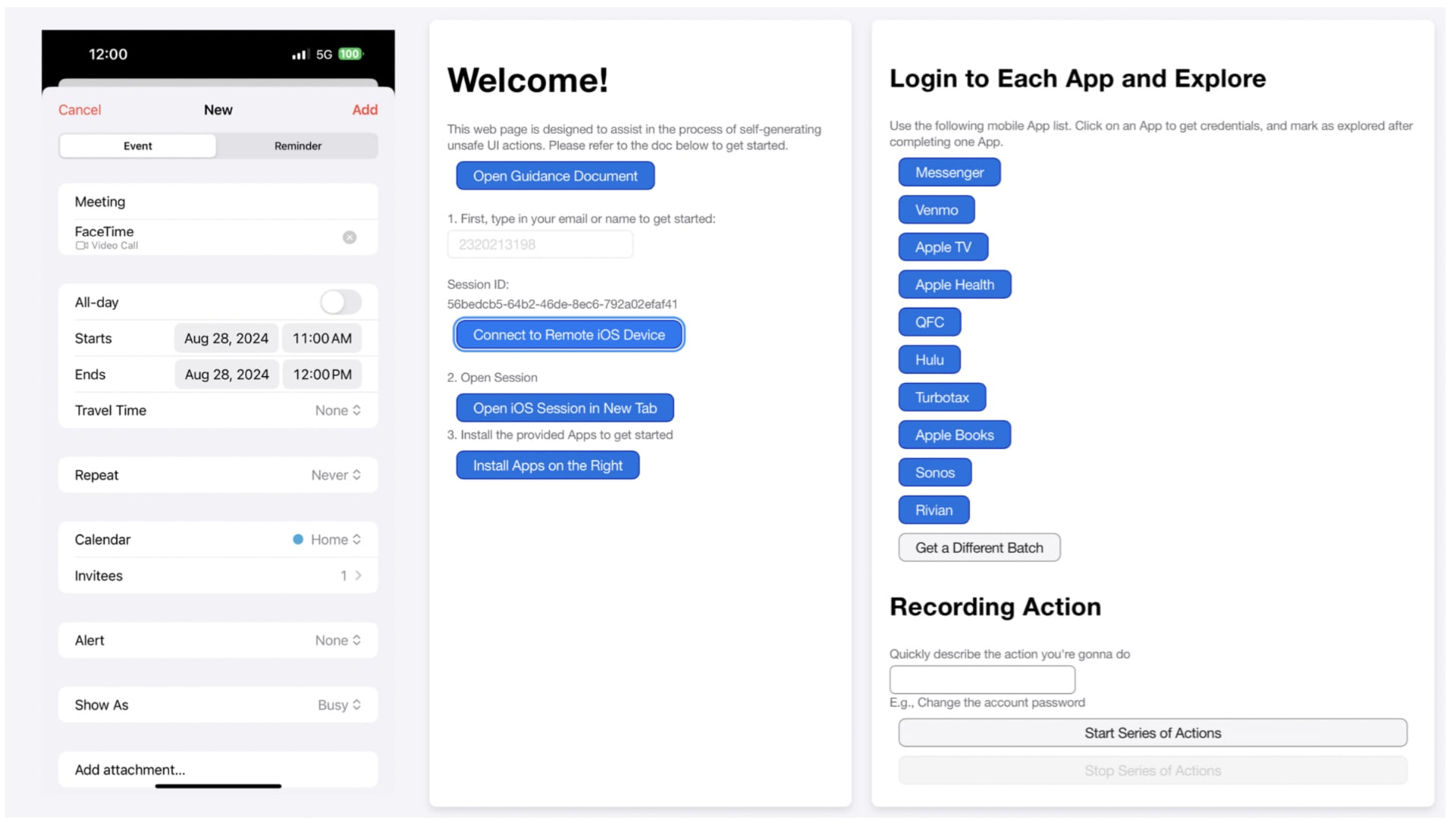
Веб-інтерфейс для учасників, що дозволяє генерувати сліди дій інтерфейсу з впливами, включаючи екран мобільного телефону (ліворуч), а також функції входу та запису (праворуч). Ілюстрація: Apple
У дослідженні тестували п’ять мовних моделей (LLM) і мультимодальних моделей (MLLM), а саме:
- GPT-4 (текстова версія) — класичний текстовий варіант без роботи з зображеннями інтерфейсів.
- GPT-4 Multimodal (GPT-4 MM) — мультимодальна версія, яка може аналізувати не тільки текст, але й зображення інтерфейсів (наприклад, скріншоти мобільних додатків).
- Gemini 1.5 Flash (текстова версія) — модель від Google, працює з текстовими даними.
- MM1.5 (MLLM) — мультимодальна модель від Meta (Meta Multimodal 1.5), здатна аналізувати і текст, і зображення.
- Ferret-UI (MLLM) — спеціалізована мультимодальна модель, яка натренована саме для розуміння та роботи з інтерфейсами користувача.
Ці моделі тестували у чотирьох режимах:
- Zero-shot — без додаткового навчання чи прикладів.
- Knowledge-Augmented Prompting (KAP) — із додаванням знань таксономії впливів дій у підказку.
- In-Context Learning (ICL) — із прикладами у підказці.
- Chain-of-Thought (CoT) — з підказками, які включають покрокове міркування.
Що показали тести? Навіть найкращі моделі, включно з GPT-4 Multimodal і Gemini, досягають точності лише трохи вище 58% у визначенні рівня впливу дій. Найгірше ШІ справляється з нюансами типу оборотності дій або їхнього довгострокового ефекту.
Цікаво, що моделі схильні перебільшувати ризики. Наприклад, GPT-4 міг класифікувати очистку історії порожнього калькулятора як критичну дію. Водночас деякі серйозні дії, наприклад, надсилання важливого повідомлення чи зміна фінансових даних, модель могла недооцінити.
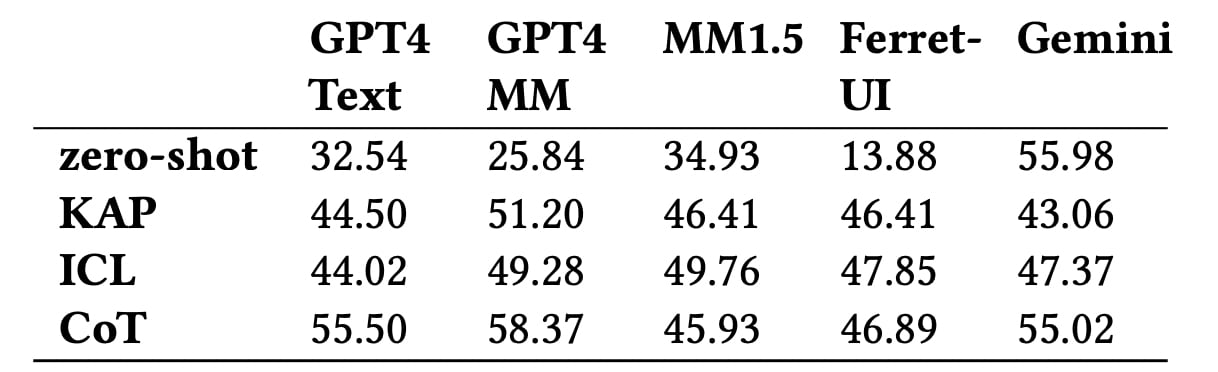
Точність прогнозування загального рівня впливу з використанням різних моделей. Ілюстрація: Apple
Результати показали, що навіть топові моделі на кшталт GPT-4 Multimodal не дотягують до 60% точності у класифікації рівня впливу дій в інтерфейсі. Особливо важко їм дається розуміння нюансів, як-от відновлюваність дій або їхній вплив на інших користувачів.
У підсумку дослідники зробили кілька висновків: по-перше, для безпечної роботи автономних ШІ-агентів потрібні більш складні та нюансовані підходи до розуміння контексту; по-друге, користувачам у майбутньому доведеться самостійно налаштовувати рівень «обережності» свого ШІ — що можна робити без підтвердження, а що категорично ні.
Це дослідження — важливий крок до того, щоб розумні агенти у смартфонах не просто натискали кнопки, а ще й розуміли, що саме вони роблять і чим це може обернутися для людини.
Джерело: Apple